TL;DR: Create 3D and 4D scenes from a single image with controllable video diffusion.





























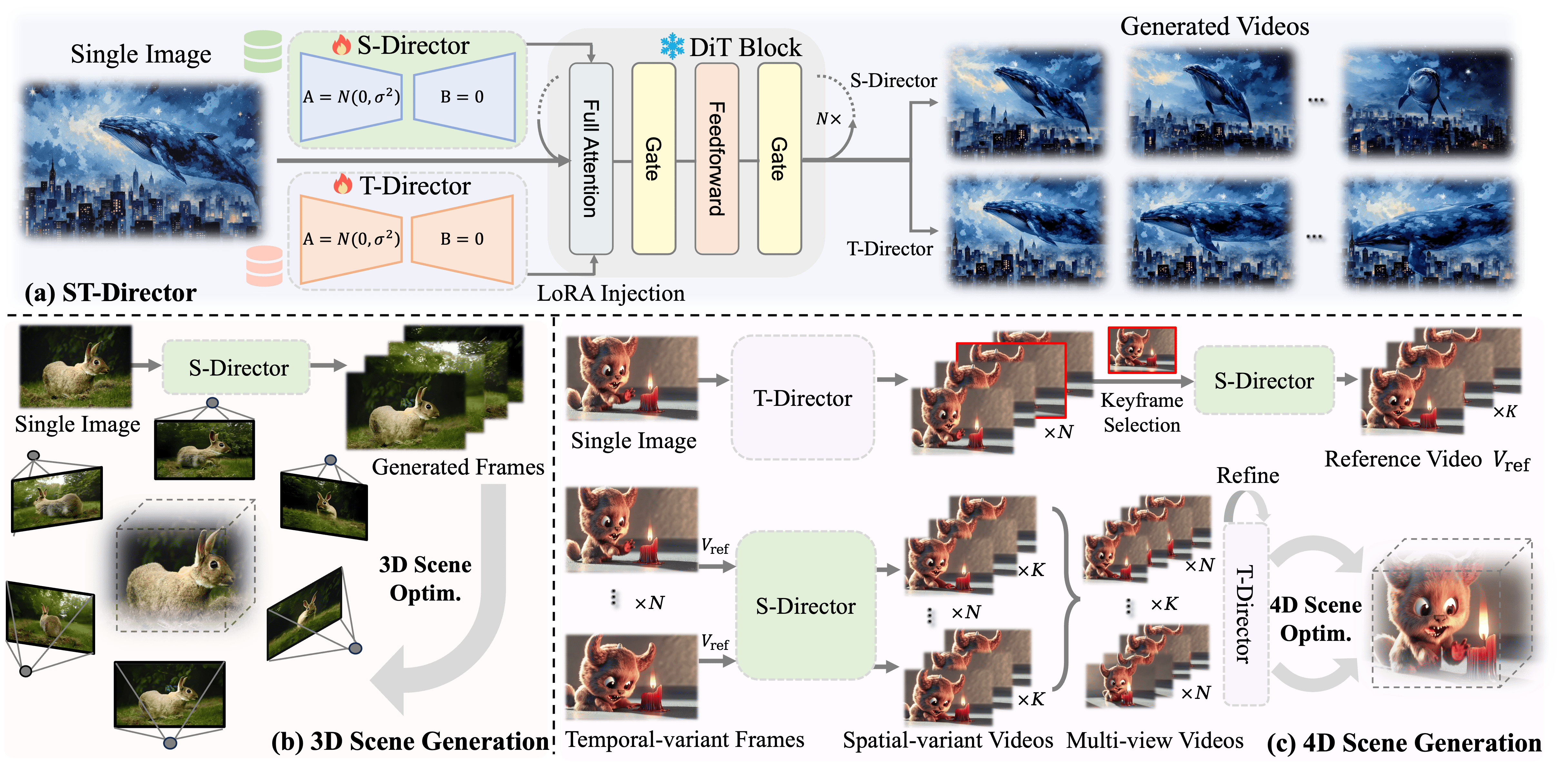
Pipeline of DimensionX. Our framework is mainly divided into three parts. (a) ST-Director for Controllable Video Generation. We introduce ST-Director to decompose the spatial and temporal parameters in video diffusion models by learning dimension-aware LoRA on our collected dimension-variant datasets. (b) 3D Scene Generation with S-Director. Given one view, a high-quality 3D scene can be recovered from the video frames generated by S-Director. (c) 4D Scene Generation with ST-Director. Given a single image, a temporal-variant video is produced by T-Director, from which a key frame is selected to generate a spatial-variant reference video. Guided by the reference video, per-frame spatial-variant videos are generated by S-Director, which are then combined into multi-view videos. Through the multi-loop refinement of T-Director, consistent multi-view videos are then passed to optimize the 4D scene.
ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model
DimensionX: Create Any 3D and 4D Scenes from a Single Image with Controllable Video Diffusion
More X Family coming soon...
@article{sun2024dimensionx,
title={DimensionX: Create Any 3D and 4D Scenes from a Single Image with Controllable Video Diffusion},
author={Sun, Wenqiang and Chen, Shuo and Liu, Fangfu and Chen, Zilong and Duan, Yueqi and Zhang, Jun and Wang, Yikai},
journal={arXiv preprint arXiv:2411.04928},
year={2024}
}